1 DE ABRIL DE 2026
La revolución silenciosa del AI local: cuando 1-bit, KV-cache y SSD-streaming convergieron
Durante las últimas semanas se acumularon avances que no son independientes — se están retroalimentando. Esta es la radiografía de lo que está pasando.
El contexto
Durante las últimas semanas se acumularon simultáneamente avances que no son independientes — se están retroalimentando. Esta semana fue particularmente intensa: Google publicó TurboQuant, Liquid AI lanzó LFM2.5-350M — un modelo state-space que dobla en capacidad a modelos del doble de su tamaño, PrismML demostró que un modelo de 8B cabe en 1.15 GB sin perder utilidad práctica, y alguien corrió un modelo de 400B parámetros en un iPhone usando SSD streaming. Ninguno de estos avances es magia — tienen una arquitectura común que vale la pena explicar.
1. TurboQuant: cómo hacer que el KV cache deje de ser el problema
Cuando un LLM procesa un contexto largo, el bottleneck no es el modelo en sí — es el KV cache, la memoria que guarda las representaciones intermedias de cada token procesado. A medida que crece el contexto, el KV cache puede ocupar más memoria que los pesos del modelo mismo. En un documento de 128K tokens, esto se vuelve insostenible.
Google Research publicó TurboQuant (arXiv:2601.04719, aceptado en ICLR 2026), un algoritmo de compresión de dos etapas que implementa 4 variantes de kernels CUDA: naive, tiled, coarsened y vectorized:
- PolarQuant: aplica una rotación ortogonal aleatoria a cada vector K y V. Esto redistribuye la información de forma más uniforme, haciendo que la cuantización posterior sea menos destructiva.
- QJL Residual Correction: una capa de corrección de error de 1 bit que absorbe el error residual de la cuantización.
El kernel vectorized logra 1,694× de speedup sobre la implementación CPU baseline, con un overhead de solo 6-58ms. El error de reconstrucción se mantiene por debajo de <0.004, y el error en attention scores es inferior a <0.1 en heads de 8K de dimensión — suficiente para no degradar la calidad del modelo.
El resultado: KV cache comprimido a 3-4 bits por elemento — 4 a 6 veces menos memoria. En un H100, hasta 8x de speedup en la computación de atención. Y lo más importante: cero pérdida de accuracy a 3.5 bits por canal, degradación marginal a 2.5 bits.
No requiere reentrenar. No requiere datos de calibración. No requiere afinar el modelo para el hardware. Es un compressor drop-in para cualquier transformer.
2. Bonsai E1M: 1-bit no es lo que pensabas
Durante años, "modelo de 1 bit" fue sinónimo de "inútil". La cuantización a 8 bits era el mínimo tolerable; por debajo era degradación catastrófica.
PrismML (spin-out de Caltech) cambió eso con Bonsai E1M: un modelo de 8.2B de parámetros donde cada peso es literalmente 1 bit — embeddings, capas de atención, MLPs, LM head. Sin atajos, sin escape a mayor precisión. 1.15 GB en total.
Para ponerlo en contexto: un 8B FP16 ocupa ~16 GB. Bonsai es 14x más pequeño y aun así compite en benchmarks con modelos como Qwen3 8B.
El truco no es solo la cuantización — es que PrismML entrenó el modelo desde cero con la constrain de 1-bit en mente. No es un modelo FP16 comprimido después. Es un modelo entrenado para ser 1-bit. La diferencia es fundamentalmente diferente.
Velocidades reales: 131 tok/s en un M4 Pro, 368 tok/s en un RTX 4090, y ~44 tok/s en un iPhone 17 Pro Max. Ese iPhone no puede correr un 8B FP16 de ninguna forma.
Lo más revelador es el Intelligence Density: Bonsai alcanza 1.06/GB, mientras que Qwen3 8B apenas llega a 0.10/GB — Bonsai es 10× más denso en inteligencia por gigabyte. No es solo que quepa más pequeño: rinde más por cada MB que ocupa.
3. Liquid LFM2.5-350M: state-space, no transformer ni MoE
Liquid AI lanzó LFM2.5-350M, la siguiente iteración de su arquitectura LFM (Liquid Foundation Model). A diferencia de los transformers vanilla o MoE, LFM usa state-space modulado en tiempo continuo. MoE activa expertos sparse por token mediante routing; LFM modula qué información persiste o decae en el estado del modelo. Son arquitecturas fundamentalmente diferentes.
Con 28T tokens de pre-training (vs 10T de LFM2), LFM2.5-350M supera consistentemente a modelos del doble de su tamaño:
| Modelo | IFEval | IFBench | BFCLv3 | CaseReportBench |
|---|---|---|---|---|
| LFM2.5-350M | 76.96 | 40.69 | 44.11 | 32.45 |
| LFM2-350M | 64.96 | 18.20 | 22.95 | 11.67 |
| Gemma 3 1B IT | 63.49 | 20.33 | 16.61 | 2.28 |
| Granite 4.0-H-350M | 61.27 | 17.22 | 43.07 | 12.44 |
En tool calling multi-turn, Distil Labs reporta +95% de accuracy al fine-tunar LFM2.5 con traces de modelos mayores. En un H100 SXM5: 40.4K tok/s ≈ 3.5B tokens/día. Para tool calling en el borde — donde no necesitas creatividad, necesitas ejecución confiable — LFM es una opción real.
4. Flash MoE: el SSD como RAM virtual para modelos masivos
La investigación de Apple "LLM in a Flash" (2023) demostró que podías correr LLMs más grandes que la RAM disponible haciendo streaming de los pesos desde el SSD. La innovación de 2026 fue combinar esto con Mixture of Experts (MoE).
Por qué importa MoE: en un MoE, solo una fracción de los expertos se activa por cada token. No necesitas cargar todos los pesos — solo los relevantes. En un modelo de 400B con 16 expertos activos por capa, solo ~6.75 MB por capa se cargan desde NVMe en cada paso.
Implementaciones recientes permiten correr 397B en un MacBook Pro con 48GB de RAM, y en iPhone 17 Pro con solo 5.5GB de RAM. El page cache del sistema operativo va cacheando los expertos recently accessed. El cuello de botella ya no es la RAM — es el bandwidth del SSD (NVMe PCIe 5.0). A medida que los SSDs modernos superan los 10 GB/s de lectura secuencial, el streaming de pesos desde almacenamiento se vuelve viable para inference en tiempo real.
Esto tiene implicaciones serias para privacidad: los datos nunca salen del dispositivo. No hay API key, no hay server, no hay logging de prompts.
5. TQ3: cuantización a nivel modelo, no solo KV cache
Un fork de llama.cpp llamado TQ3 (TurboQuant-3) extiende la matemática de TurboQuant a la cuantización de pesos del modelo completo, no solo del KV cache.
TQ3_1S es un formato de 3.5 bits por peso usando Walsh-Hadamard rotation y dual-scale encoding. Para Qwen3.5-27B: 12.9 GB (vs 14.4 GB en Q4_0), con perplejidad prácticamente idéntica en wiki.test.raw (7.2570 vs 7.2431). La diferencia: 1.5 GB menos, misma calidad. En una GPU de 16GB, esto significa que el modelo cabe completo en VRAM sin offloading parcial.
6. Unsloth Dynamic 2.0: quantización por capa para todos los modelos
La versión anterior de Unsloth Dynamic funcionaba bien solo en MoE. Dynamic 2.0 extiende quantización específica por capa a todos los modelos — dense y MoE. Cada capa tiene su propio scheme basado en +1.5M tokens de dataset hand-curated de alta calidad.
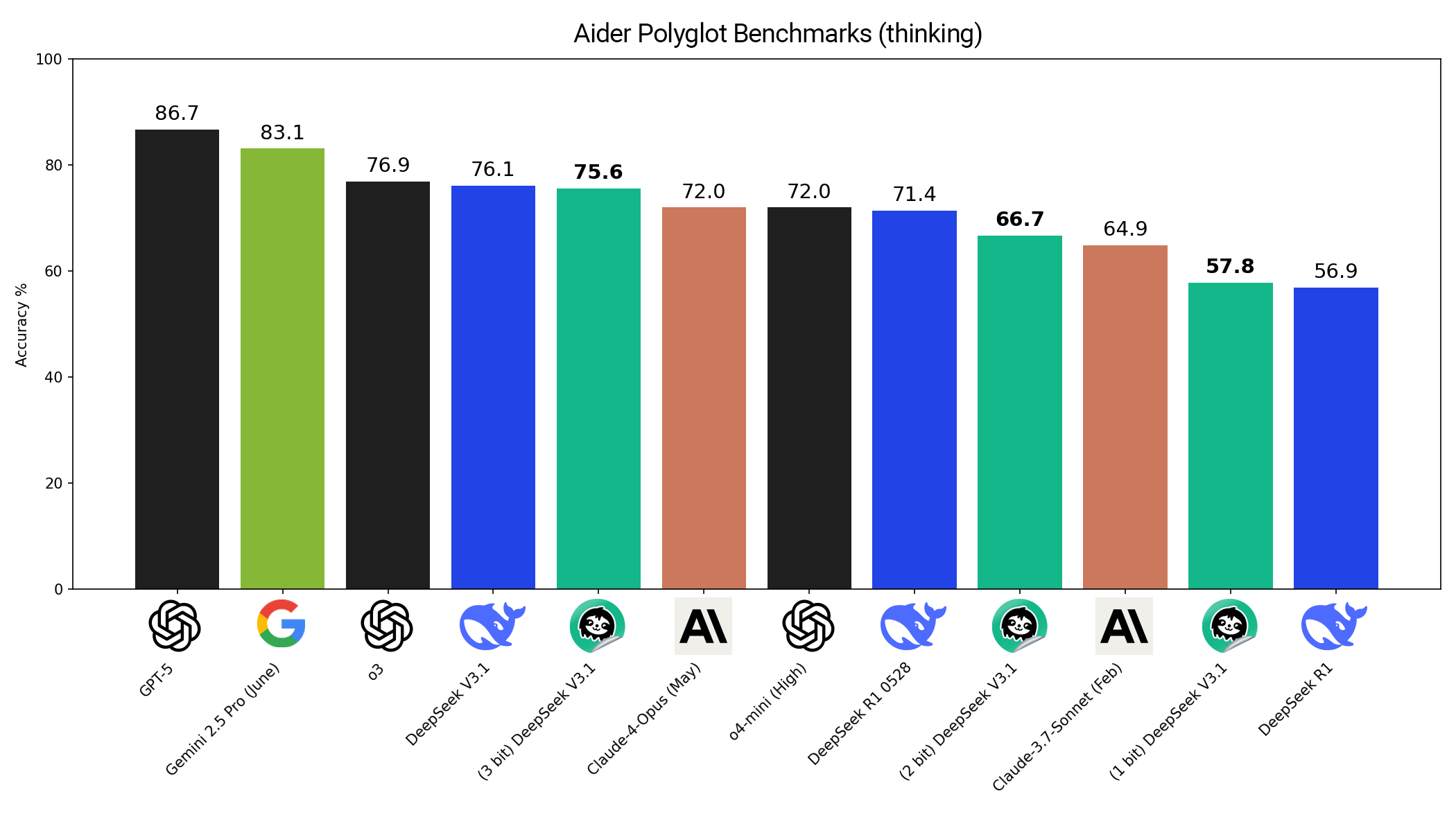
La métrica clave ya no es solo accuracy — es KL Divergence, que mide cuánto "flipa" el modelo cuantizado vs el original (no solo qué tan cerca está en respuestas exactas). Unsloth Dynamic 2.0 supera a otros métodos de cuantización tanto en KL Divergence como en accuracy, siendo ~8GB más pequeño que la versión no-Unsloth con mejor accuracy.
Lo notable: DeepSeek V3.1 a 3 bits logra 75.6% en Aider Polyglot, compitiendo con modelos full-precision. Disponible como GGUF en llama.cpp y LM Studio.
7. Attention Matching: 50× menos entradas en el KV cache
Paper de DeepMind y Multi-Channel publicado esta semana: Fast KV Compaction via Attention Matching (arXiv:2602.16284).
Hasta ahora había dos approaches para comprimir el KV cache: reducir bits por elemento (TurboQuant, 4-6×) o simplemente descartar tokens (lossy, degradaba rápido). Cartridges propuso compresión en espacio latente con alta calidad pero needing gradient-based optimization que tomaba horas por contexto.
Attention Matching logra lo mismo que Cartridges — hasta 50× de compactación — pero en segundos, no horas. Sin gradient descent. Tiene soluciones closed-form para reproducir el output de atención y el attention mass por cada KV head.
Y es ortogonal a TurboQuant: una reduce bits, la otra reduce entradas. Se apilan.
En la práctica: puedes tener un KV cache 50× más pequeño Y los bits que quedan 4× más comprimidos. Eso es 200× menos memoria de KV cache en el caso extremo.
Por qué todo esto importa ahora y no por separado
Estos avances no son independientes — se apilan de formas específicas:
| Técnica | Qué resuelve | Cuánto |
|---|---|---|
| Bonsai E1M | Tamaño de pesos (entrenado 1-bit) | 14x reducción |
| Unsloth Dynamic 2.0 | Cuantización por capa, todos los modelos | 3-bit competitivo con FP |
| TQ3 | Pesos con Walsh-Hadamard rotation | ~1.2x reducción adicional |
| TurboQuant (KV) | Bits por elemento del KV cache | 4-6x reducción |
| Attention Matching | Entradas del KV cache | 50x reducción |
| Flash MoE / SSD streaming | Límite de RAM | Modelos 100x más grandes |
| LFM2.5-350M | Arquitectura state-space eficiente | 350M con capacidad 1B+ |
La combinación práctica:
- Un 8B entrenado en 1-bit (Bonsai) → 1.15 GB
- Con KV cache turboquantizado (TurboQuant) → contexto largo sin explotar RAM
- Con quantización de 3.5 bits para otros modelos (TQ3) → 27B cabe en 12.9 GB en vez de 14.4 GB
- Con SSD streaming (Flash MoE) → un 400B corre en un teléfono
Esto significa que el punto de quiebre de "útil localmente" se movió dramáticamente en semanas. Lo que hace 6 meses requería una GPU de $5,000, hoy corre en hardware que ya tienes en el bolsillo.
Qué viene
Apple ya está integrando esto en su roadmap para Siri potenciada por LLM (esperado para finales de 2026). Qualcomm optimiza para Snapdragon. AMD para Ryzen AI. Qualcomm, AMD, Intel y Apple mismo tienen soporte día cero para LFM2.5.
Del lado open source, llama.cpp incorpora las técnicas de TQ3 y turboquantización. MLX de Apple ya tiene implementaciones optimizadas para Apple Silicon.
El impacto en la industria de chips está siendo discutido: si el KV cache se comprime 6x y los pesos 14x, la demanda de HBM está cambiando de forma. No desaparece — pero los requisitos de memoria por token de contexto se reconfiguran radicalmente.
Conclusión
La narrativa de "local AI = modelos débiles incapaces" se está derrumbando. No por magia ni por marketing — por una convergencia real de investigación en cuantización, arquitecturas sparse, y técnicas de inference engine. Lo que estamos viendo no es una mejora incremental. Es un cambio de régimen.
El iPhone que tienes en la mano hoy podría estar corriendo un modelo con capacidad de GPT-3.5 en los próximos 12 meses. No en la nube. En el dispositivo. Sin conexión. Sin que nadie vea lo que le preguntas.
La pregunta ya no es si puedes correr LLMs localmente. La pregunta es por qué seguirías pagando por API keys para datos sensibles.
REFERENCIAS
- TurboQuant — GPU-Accelerated INT8 Quantization for KV Cache (arXiv)
- PrismML — The First Commercially Viable 1-bit LLMs
- Liquid AI — LFM2.5-350M: No Size Left Behind
- TQ3 — llama.cpp fork with WHT quantization
- Attention Matching — Fast KV Compaction (DeepMind)
- Unsloth Dynamic 2.0 GGUFs
- CUDA KV Cache Compression (Google Research)